What I learned while studying for the GCP PDE exam
 |
| GCP PDE Badge |
I recently (June 22nd, 2024) appeared for and passed the GCP Professional Data Engineer certification. [1] In this blog, I'd like to share what I've learned in studying for and taking the exam.
First off, here are the main GCP offerings that are tested on the exam:
- BigQuery: This is a data warehouse that can hold structured data. It is SQL compliant and you can perform data analysis with this tool. Despite seeming like a regular relational database, it is actually a columnar database. This database can go up-to petabyte scale!
- BigTable: Despite have 'Table' in the name, it's a NoSQL database. It is a non-relational database used for things like receiving large amounts of IoT/factory sensors' data, user's application data, etc. Got to learn about BigTable schema design (& especially row-key optimization)
- Cloud Storage: This service was covered even in the Cloud Associate Engineer exam but it's just a blob (Binary Large OBject) storge like Amazon S3 that is designed to store unstructured data like images, videos, audio files, etc. It has different storage classes & availability choices.
- Firestore: NoSQL document database used for mobile, web, & server deployments.
- Memorystore: Fully managed Redis & Memcached for sub-milliseconds latency.
- CloudSQL: Managed service for MySQL, PostgreSQL, & SQL server.
- Spanner: SQL database when you need global consistency for use cases like gaming, global finances, supply chain/retail, etc.
- Dataprep (by Trifacta): This tool let's you explore different datasets and create 'recipes' that let you transform data. It can be used for cleaning & transforming raw data into a format ready for analysis.
- Cloud Data Fusion: It is a date integration service that helps users build & manage data pipelines with GUI. In the visual interface, you drag-and-drop pre-built connectors that have the logic to do things like read from sources such as databases, perform calculcation, write to sinks, etc.
- Dataproc: For managed Hadoop & Spark clusters.
- Dataflow: This is GCP's managed service for Apache Beam which is an open source unified programming model to define and execute data processing pipelines, including ETL, batch and stream processing.
- Cloud Composer: This is GCP's manged service for Apache Airflow which is an open-source workflow management platform for data engineering pipelines.
- Pub/Sub: This is like Apache Kafka, there are publishers & subscribers and topics to which messages are published. It can be done is pull/push manner and at least once delivery is guaranteed.
You can find the exam guide here.
Cheat Sheet:
 |
| Quick reference for GCP tool selection |
BigQuery & GoogleSQL:
Learned how it's important to reduce to the amount of data scanned to get results faster (& be charged less!). This can be done with Partitioned tables (segmenting data). You can partition based on an integer range values such as customer_id, time-unit column, or ingestion time. It's also possible to optimize queries using clustered tables where there's a user-defined column sort order.
It's also imperetive to optimize JOINs which can otherwise be resource-intensive. This can be done by using FILTER clauses (reducing data processed) and using WITH clauses. Also, avoid CROSS JOINs which produces cartesian product which can end up being a lot unnecessary rows!
There's a feature called 'EXPLAIN' which provides detailed query execution plan. We can use this to identify bottlenecks & optimize queries.
See this link to learn more about query optimization for BigQuery.
Machine Learning using BigQuery
BigQuery also has built-in capabilities to build, train, and deploy machine learning models directly within the BigQuery environment. You can create models with the 'CREATE MODEL' clause, train, evaluate, & use for Prediction.

Got to learn about linear regression which predicts continuous outcomes based on input features such as sales prediction and logistic regressions which is used for binary outcomes such as malignant/bening tumors.
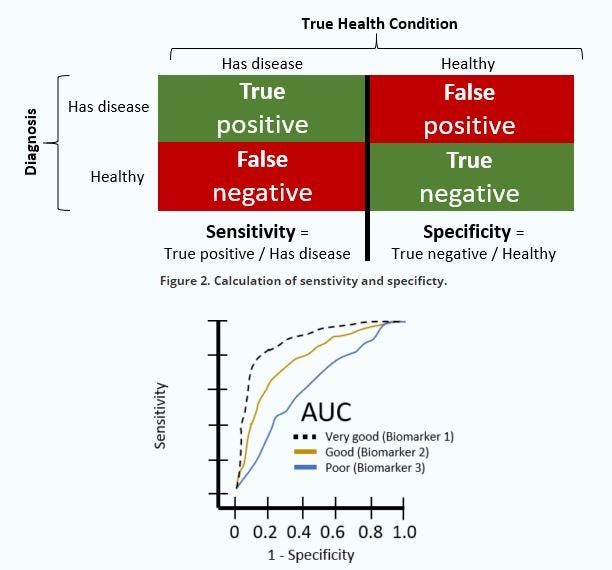
Learned briefly about model evaluation and AUC-ROC (Area under the curve - receiver operating characteristic).
Dataproc (Hadoop & Spark):
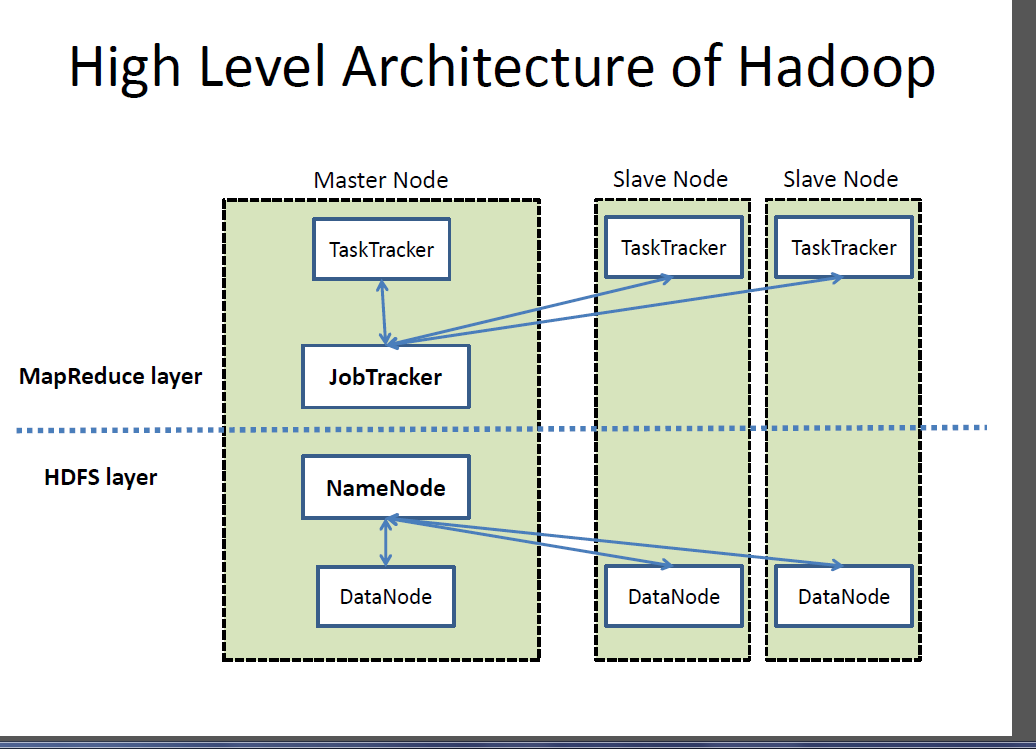
It was very interesting to learn about Hadoop which was invented to deal with large data and the computing & storage limitations. Hadoop enables distributed storage (through HDFS) and processing (throught MapReduce).
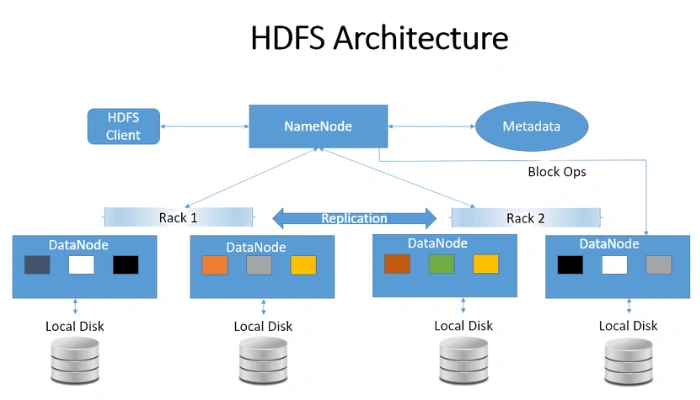
Hadoop Distributed FileSystem is a distributed file system that stores data across multiple machines & provides high throughput access to data.
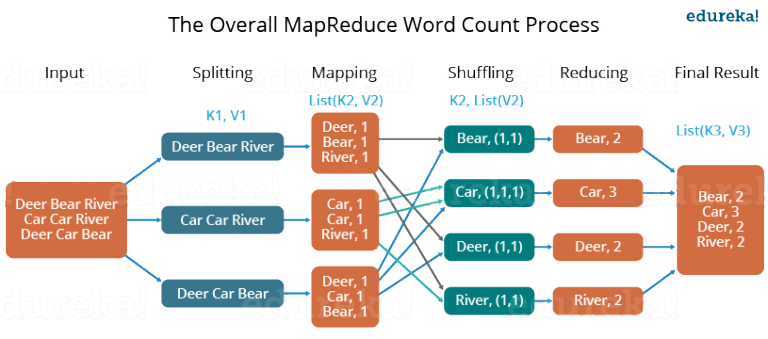
MapReduce is a programming model & processing engine for large-scale data processing. It breaks down a large task into smaller ones and processes them in parallel.
Hadoop uses YARN (Yet Another Resource Negotiator) for scheduling jobs. This is what enables distributed processing.
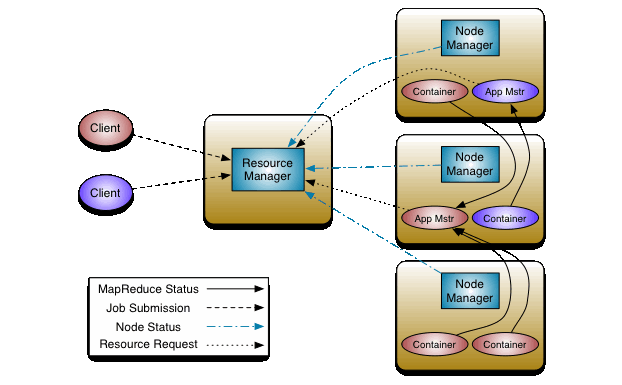
Apache Spark is an analytics engine for big data processing with modules. It does in-memory computing which makes it very fast.

Dataproc is a managed-GCP service what this means is that you just select how much resources (computing, memory, & storage) that you need and the underlying tools will be installed and provided for you. This reduces the amount of time to get the cluster up & running. Also, since we would be able to leverage GCP's massive infrastructure, we would get great scaling capabilities.
It was also fascinating to learn about GCP's Colossus file system and Jupiter network which has petabit-scale bi-sectional bandwidth! 😮
Dataflow (data processing pipelines):
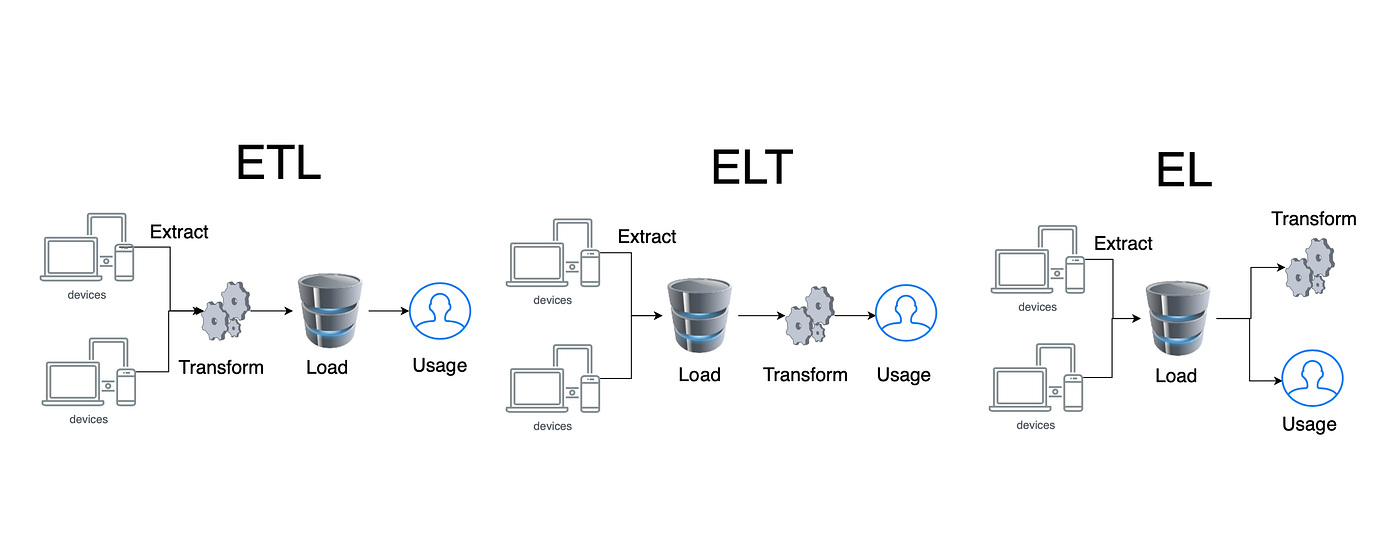
Data processing pipelines are used to convert raw data into meaningful, usable information. for analytics workflows. There are batch pipelines (regular intervals) & stream pipelines (continuous). There are different types of loading, ETL, ELT, or EL. ETL should be used when the transformation takes significant amount of work such as performing some computing/logic/appending other information to derive insights, etc. while ETL should be used if you can get what you want with a simple query like, loading all sales data and getting cumulative sales for the day. EL can be used when there isn't any transformation required.
If you don't have an on-premises Hadoop/Spark clusters that you are migrating to GCP, it's recommended to use dataflow pipelines instead. Dataflow uses Beam programming model.
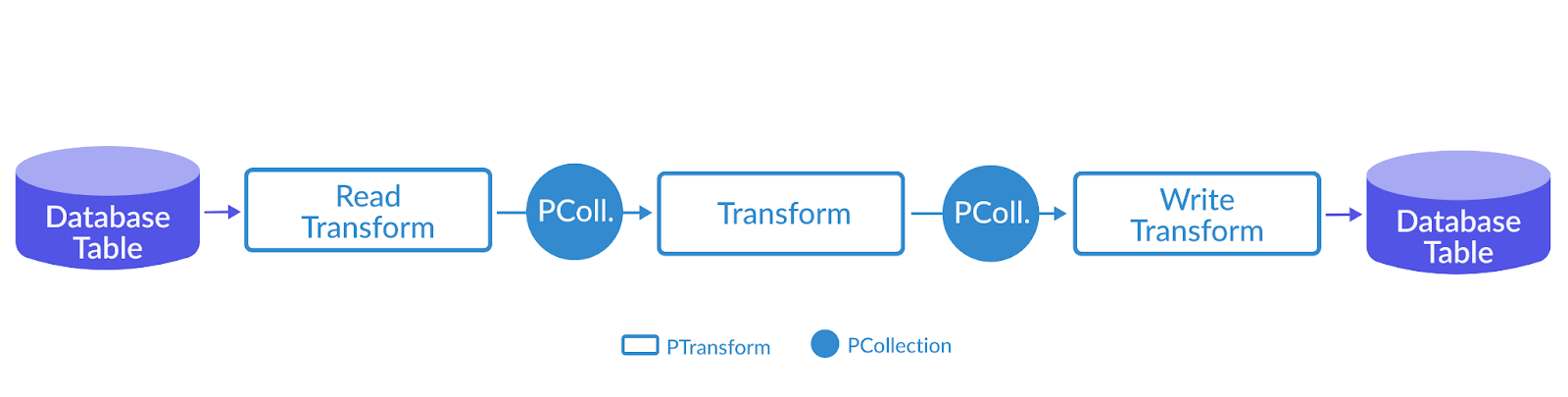
It's a fully-managed service with automatic scaling and integrated with other GCP services for sources/sinks. It also has built-in monitoring and logging.
Summary:
These are just some of the services that I learned about and had my interest peeked by. There are a lot more services in GCP that enable different workflows. I think these tools are great to store & process data, derive insights, enable automation, and most importantly solve business problems.
Thank you for reading! Let me know your thoughts in the comments.
---
Resources:
[1] https://cloud.google.com/learn/certification/guides/data-engineer


Comments
Post a Comment